Minimax, Expectimax.
Pac-Man, now with ghosts.
Minimax, Expectimax.
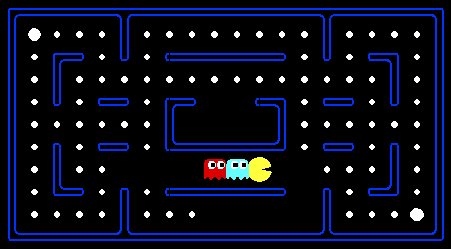
For those of you not familiar with Pac-Man, it's a game where Pac-Man (the yellow circle with a mouth in the above figure) moves around in a maze and tries to eat as many food pellets (the small white dots) as possible, while avoiding the ghosts (the other two agents with eyes in the above figure). If Pac-Man eats all the food in a maze, it wins. The big white dots at the top-left and bottom-right corner are capsules, which give Pac-Man power to eat ghosts in a limited time window, but you won't be worrying about them for the required part of the assignment. You can get familiar with the setting by playing a few games of classic Pac-Man, which we come to just after this introduction.
In this assignment, you will design agents for the classic version of Pac-Man, including ghosts. Along the way, you will implement both minimax and expectimax search.
The base code for this assignment contains a lot of files, which
are listed towards the end of this page; you, however, do not need to
go through these files to complete the assignment. These are present only to
guide the more adventurous amongst you to the heart of Pac-Man. As in previous
assignments, you will only be modifying submission.py.
Ensure that you're using Python version 3.7.5. If you have a different version, you might experience GUI-related issues. Check your Python version by running:
python --version
.exe file to start the installation.chmod +x Miniconda3-latest-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh
.pkg file to start the installation.After installing Miniconda, set up your environment with the following commands:
conda create --name pacman python=3.7.5
conda activate pacman
If you have a Macbook with an M1 chip and are getting errors, please follow the endorsed steps on this Ed Post
Important:change the python version from python=3.7 to python=3.7.5. You may need to run commands with python3 instead of python, e.g.
python3 pacman.py
We've created a LaTeX template here for you to use that contains the prompts for each question.
grader.py included is useful to verify whether or not your solution crashes due to bugs or to verify Pac-Man behavior,
but will not give reliable information on whether your submission will time out on any of the tests.
We included a number of 0-point basic tests that will replicate the behavior of the hidden tests,
but only give feedback on whether or not your solution times out. To properly ensure that your implementation will not
time out, please make sure to do test submissions on Gradescope and observe the results on these 0-point tests.
First, play a game of classic Pac-Man to get a feel for the assignment:
python pacman.pyYou can always add
--frameTime 1 to the command line
to run in "demo mode" where the game pauses after
every frame.
Now, run the provided ReflexAgent in submission.py:
python pacman.py -p ReflexAgentNote that it plays quite poorly even on simple layouts:
python pacman.py -p ReflexAgent -l testClassicYou can also try out the reflex agent on the default
mediumClassic layout with one ghost or two.
python pacman.py -p ReflexAgent -k 1
python pacman.py -p ReflexAgent -k 2
Note: You can never have more ghosts than the layout permits.
Options: Default ghosts are random; you can also play for fun with slightly smarter directional ghosts using -g DirectionalGhost. You can also play multiple games in a row with -n. Turn off graphics with -q to run lots of games quickly.
Now that you are familiar enough with the interface, inspect the ReflexAgent code carefully (in submission.py) and make sure you understand what it's doing. The reflex agent code provides some helpful examples of methods that query the GameState: A GameState object specifies the full game state, including the food, capsules, agent configurations, and score changes: see submission.py for further information and helper methods, which you will be using in the actual coding part. We are giving an exhaustive and very detailed description below, for the sake of completeness and to save you from digging deeper into the starter code. The actual coding part is very small -- so please be patient if you think there is too much writing.
Note: If you wish to run the game in the terminal using a text-based interface,
check out the terminal directory.
Note 2: If the action tiebreaking is done deterministically for Problems 1, 2, and 3, running on the mediumClassic map may cause mostly losses. This is alright since the grader test cases don’t run on these layouts.
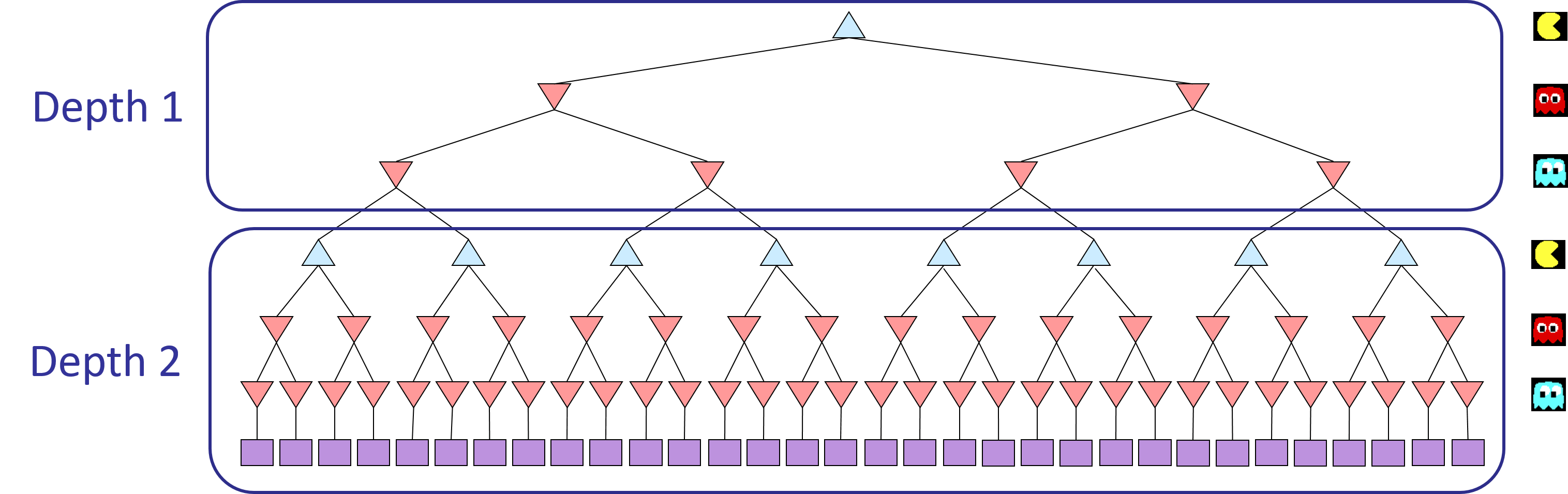
Formally, consider the limited depth tree minimax search with evaluation functions taught in class. Suppose there are $n+1$ agents on the board, $a_0,\ldots , a_n$, where $a_0$ is Pac-Man and the rest are ghosts. Pac-Man acts as a max agent, and the ghosts act as min agents. A single depth consists of all $n+1$ agents making a move, so depth 2 search will involve Pac-Man and each ghost moving two times. In other words, a depth of 2 corresponds to a height of $2(n+1)$ in the minimax game tree (see diagram below).
Comment: In reality, all the agents move simultaneously. In our formulation, actions at the same depth happen at the same time in the real game. To simplify things, we process Pac-Man and ghosts sequentially. You should just make sure you process all of the ghosts before decrementing the depth.
Before diving into the recurrence, let's understand our notation. In the recurrence for $V_{\text{minmax}}(s,d)$, $s$ represents the current state, and $d$ represents the current depth in the game tree, with $d = 0$ indicating the root of the tree (initial state) and increasing as we go deeper into the tree.
Write the recurrence for $V_{\text{minmax}}(s,d)$ in math as a piecewise function. You should express your answer in terms of the following functions:MinimaxAgent class in
submission.py using the above recurrence.
Remember that your minimax
agent (Pac-Man) should work with any number of ghosts, and your minimax tree should have
multiple min layers (one for each ghost) for every max layer.
Your code should be able to expand the game tree to any given depth. Score the
leaves of your minimax tree with the supplied
self.evaluationFunction, which defaults to
scoreEvaluationFunction. The class
MinimaxAgent extends MultiAgentSearchAgent, which
gives access to self.depth and
self.evaluationFunction. Make sure your minimax code makes
reference to these two variables where appropriate, as these variables are
populated from the command line options.
Implementation Hints
self.index in your minimax implementation to refer to the Pac-Man's index.
Notice that only Pac-Man will actually be running your MinimaxAgent.
GameStates, either passed in
to getAction or generated via
GameState.generateSuccessor. In this assignment, you will not be
abstracting to simplified states.
ReflexAgent
and MinimaxAgent useful.
GameState.getScore.
self.evaluationFunction), and you should call this function without changing it. Use self.evaluationFunction in your definition of $V_\text{minmax}$ wherever you used $\text{Eval}(s)$ in part $1a$. Recognize that now we're evaluating states rather than actions. Look-ahead agents evaluate future states whereas reflex agents evaluate actions from the current state. minimaxClassic layout are 9, 8, 7, and -492 for depths 1, 2, 3, and 4, respectively (passed into the “-a depth=[depth]” argument). You can use these numbers to verify whether your implementation is correct. To verify, you can print the minimax value of the state passed into getAction and check if the value of the initial state (first value that appears) is equal to the value listed above. Note that your Pac-Man agent will often win, despite the dire prediction of depth 4 minimax search, whose command is shown below. With depth 4, our Pac-Man agent wins 50-70% of the time. Depths 2 and 3 will give a lower win rate. Be sure to test on a large number of games using the -n and -q flags.
python pacman.py -p MinimaxAgent -l minimaxClassic -a depth=4
These questions and observations are here for you to ponder upon; no need to include in the write-up.
openClassic and
mediumClassic (the default), you'll find Pac-Man to be good at not
dying, but quite bad at winning. He'll often thrash around without making
progress. He might even thrash around right next to a dot without eating it.
Don't worry if you see this behavior. Why does Pac-Man thrash around right next to a dot? AlphaBetaAgent. Again, your algorithm will be slightly more
general than the pseudo-code in the slides, so part of the challenge is to
extend the alpha-beta pruning logic appropriately to multiple ghost agents.
You should see a speed-up: Perhaps depth 3 alpha-beta will run as fast as
depth 2 minimax. Ideally, depth 3 on mediumClassic should run in
just a few seconds per move or faster. To ensure your implementation does not time out,
please observe the 0-point test results of your submission on Gradescope.
python pacman.py -p AlphaBetaAgent -a depth=3
The AlphaBetaAgent minimax values should be identical to the
MinimaxAgent minimax values, although the actions it selects can
vary because of different tie-breaking behavior. Again, the minimax values of
the initial state in the minimaxClassic layout are 9, 8, 7, and
-492 for depths 1, 2, 3, and 4, respectively. Running the command given above this
paragraph, which uses the default mediumClassic layout,
the minimax values of the initial state should be 9, 18, 27, and 36
for depths 1, 2, 3, and 4, respectively. Again, you can verify by printing the minimax
value of the state passed into getAction. Note when comparing the time
performance of the AlphaBetaAgent to the MinimaxAgent, make
sure to use the same layouts for both. You can manually set the layout by adding for
example -l minimaxClassic to the command given above this paragraph.
ExpectimaxAgent, where your Pac-Man agent no longer assumes ghost agents take actions that minimize Pac-Man's utility. Instead, Pac-Man tries to maximize his expected utility and assumes he is playing against multiple RandomGhosts, each of which chooses from
getLegalActions uniformly at random.
You should now observe a more cavalier approach to close quarters with ghosts. In particular, if Pac-Man perceives that he could be trapped but might escape to grab a few more pieces of food, he'll at least try.
python pacman.py -p ExpectimaxAgent -l trappedClassic -a depth=3You may have to run this scenario a few times to see Pac-Man's gamble pay off. Pac-Man would win half the time on average, and for this particular command, the final score would be -502 if Pac-Man loses and 532 or 531 (depending on your tiebreaking method and the particular trial) if it wins. You can use these numbers to validate your implementation.
Why does Pac-Man's behavior as an expectimax agent differ from his behavior as a minimax agent (i.e., why doesn't he head directly for the ghosts)? We'll ask you for your thoughts in Problem 5.
betterEvaluationFunction.
The evaluation function should evaluate states rather than actions.
You may use any tools at your disposal for evaluation, including any util.py code
from the previous assignments. With depth 2 search, your evaluation function
should clear the smallClassic layout with two random ghosts more
than half the time for full (extra) credit and still run at a reasonable rate.
python pacman.py -l smallClassic -p ExpectimaxAgent -a evalFn=better -q -n 20For this question, we will run your Pac-Man agent 20 times with a time limit of 10 seconds and your implementations of questions 1-3. We will calculate the average score you obtained in the winning games. You obtain 1 extra point per 100 point increase above 1200 in your average winning score, for a maximum of 5 points. In
grader.py, you can see how extra credit is awarded.
For example, you get 2 points if your average winning score is between 1400 and 1500.
In addition, the top 3 people in the class will get additional points of extra credit: 5 for the winner, 3 for the runner-up, and 1 for third place.
Note that late days can only be used for non-leaderboard extra credit. If you want to get extra credit from the leaderboard, please submit before the normal deadline. Hints and Observations
betterEvaluationFunction should run in the same time limit as the other problems.
pacman.pdf, not in code comments. Note that you can attempt this question only if you have implemented a different evaluation function in part (a) above.
Before diving into the problem, it would be beneficial to refer to the AI alignment module to gain deeper insights and context:
In this problem we'll revisit the differences
between our minimax and expectimax agents, and
reflect upon the broader consequences of AI misalignment: when our agents don't do what we want them to do, or
technically do, but cause unintended consequences along the way. Going back to Problem 4, consider the following runs of the
minimax and expectimax agents on the small
trappedClassic environment:
python pacman.py -p MinimaxAgent -l trappedClassic -a depth=3
python pacman.py -p ExpectimaxAgent -l trappedClassic -a depth=3
Be sure to run each command a few times, as there is some randomness in the environment and the agents' behaviors, and pay attention, as the episode lengths can be quite short. What you should see is that the minimax agent will always rush towards the closest ghost, while the expectimax agent will occasionally be able to pick up all of the pellets and win the episode. (If you don't see this behavior, your implementations could be incorrect!) Then answer the following questions:
scoreEvaluationFunction) and/or the default utility function $\text{Utility}(s)$ (i.e. the final game score) that would prevent the minimax agent from dying instantly in the trappedClassic environment, and behave more closely to that of the expectimax agent.
GameState object, or give concrete numbers; just describe the hypothetical change in the functions. An answer which suggests changes to how the game score is computed itself (which both $\text{Eval}(s)$ and $\text{Utility}(s)$ depend upon) will also be accepted.
Go Pac-Man Go!
Files:submission.py |
Where all of your multi-agent search agents will reside, and the only file that you need to concern yourself with for this assignment. |
pacman.py
| The main file that runs Pac-Man games. This file also describes a Pac-Man
GameState type, which you will use extensively in this assignment. |
game.py |
The logic behind how the Pac-Man world works. This file describes several supporting types like
AgentState, Agent, Direction, and Grid. |
util.py |
Useful data structures for implementing search algorithms. |
graphicsDisplay.py |
Graphics for Pac-Man. |
graphicsUtils.py |
Support for Pac-Man graphics. |
textDisplay.py |
ASCII graphics for Pac-Man. |
ghostAgents.py |
Agents to control ghosts. |
keyboardAgents.py |
Keyboard interfaces to control Pac-Man. |
layout.py |
Code for reading layout files and storing their contents. |
search.py, searchAgents.py, multiAgentsSolution.py |
These files are not relevant to this assignment and you do not need to modify them. |
[1] For more examples of reward hacking (or "specification gaming"), see this article from DeepMind and this list of concrete examples of reward hacking observed in the AI literature.